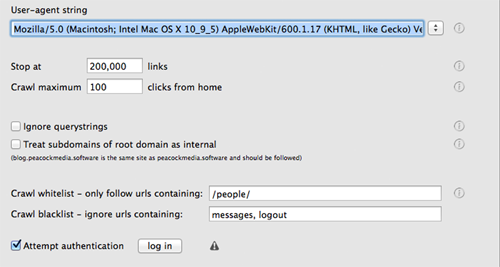
WebScraper uses the Integrity v6 Engine to quickly scan a website, and can output the data (currently) as csv or json. The output can include various meta data, the entire content of each page (as text, html or markdown) and can extract parts of the pages (currently a named class, id or itemprop of divs, spans, dd's or p's). Webscraper is new. Please use it for free and please get in touch with any requests, bug reports or observations. Easy to scan a site - just enter the starting url and press Go Easy to export - checkboxes for the columns you want Plenty of options / configuration Configuration of various limits on the crawl and the output file size